وقتی مدل یادگیری ماشین را برای تولید استفاده میکنید، به سرعت متوجه میشوید که کار هنوز تمام نشده است و به بسیاری از جهات نیاز به بهبود دارد. چگونه میتوانید اطمینان پیدا کنید که مدلهایتان همانطور که انتظار دارید عمل میکنند؟ در طول زمان، هنگامی که رفتار مشتری شما در آینده تغییر میکند و دادههای آموزشی شما قدیمی میشوند، چگونه با این چالشهای پیچیده مقابله کنید؟ همه اینها با توجه به واقعیتی که ابزارها و تکنیکهای نظارت بر یادگیری ماشین به سرعت در حال تکامل است، مسأله را بسیار پیچیدهتر میکند. نظارت یک تلاش چندجانبه است که میتواند در حوزههای مختلفی از علوم داده، مهندسی، DevOps و تجارت معنا و کاربرد داشته باشد. به دلیل ترکیب پیچیدگی و ابهام در این زمینه، تعجبی ندارد که بسیاری از دانشمندان داده و مهندسان یادگیری ماشین در مورد نظارتهای خود در طول زمان مطمئن نباشند.
چرخه عمر سیستم یادگیری ماشین
نظارت بر مدلهای یادگیری ماشین به روشهایی اشاره دارد که امکان درک و ردیابی عملکرد مدل را از دو جنبه علم داده و عملیاتی فراهم میآورد. نظارت ناکافی میتواند منجر به عدم کنترل مدلهای نادرست در فرآیند تولید، استفاده از مدلهای قدیمی که ارزش تجاری افزوده ندارند، یا شناسایی نکات ظریف در مدلهایی که در طول زمان به وجود میآیند و هیچگاه رفع نمیشوند، شود. زمانی که یادگیری ماشین هسته اصلی فعالیتهای شرکت شما است، عدم توانایی در تشخیص این نوع اشکالات میتواند به عنوان یک نقص جدی در عملکرد شرکت در نظاممندیهای معمول باشد.
مفهوم تحویل پیوسته برای یادگیری ماشین (CD4ML) که توسط Martin Fowler معرفی شده است، نموداری بصری و مفید را برای نمایش چرخه حیات یک مدل یادگیری ماشین و نقش نظارت در آن ارائه میدهد. این نمودار شش مرحله متمایز در چرخه عمر یک مدل یادگیری ماشین را نشان میدهد:
- ساختار مدل: در این مرحله، مسأله را درک، دادهها را آماده، و ویژگیها را مهندسی میکنیم. حال با استفاده از زبان برنامهنویسی مورد نظر، کد اولیه را تولید میکنیم.
- ارزیابی و آزمایش مدل: در این مرحله، ویژگیها را انتخاب، پارامترهای مرتبط را تنظیم، و اثربخشی الگوریتمهای مختلف را بر روی مسأله موردنظر مقایسه میکنیم. این مرحله شامل آمار و نمودارهایی است که به میزان تأثیر ویژگیها، دقت، صحت و منحنی مشخصه عملکرد سیستم (ROC) پرداخته است.
- تولید مدل: در این مرحله، از یافته های خود در تحقیقاتی که در مرحله قبل انجام شده است استفاده میکنیم و مدل اولیه خود را برای اجرا و استقرار آماده میکنیم. نمونههای این مرحله شامل کدهایی هستند که در برخی موارد در یک زبان برنامهنویسی مشخص یا چارچوبی کاملاً متفاوت نوشته میشوند.
- تست: در این مرحله، از صحت عملکرد کد تولید شده اطمینان حاصل میکنیم. نتایج بهدست آمده در این مرحله بابستی با نتایج مشاهده شده در مرحله ارزیابی و آزمایش مدل مطابقت داشته باشد.
- استقرار: در این مرحله، از بهرهبرداری میشود و با ارائه پیشبینیهای مربوطه، ارزش افزوده مورد نظر ما تولید میشود. علاوه بر مدل یادگیری تولید شده، مواردی نظیر رابط برنامهنویسی کاربردی، امنیت، مدیریت پایگاه داده و … نیز مورد توجه قرار میگیرند.
- نظارت و مشاهده: این مرحله نهایی برای اطمینان از عملکرد مدل یادگیری ماشین در محیط تولید است که موضوع اصلی این پست وبلاگ است. در این مرحله، نظارت بر مدل و مشاهده عملکرد آن در محیط تولید انجام میشود.
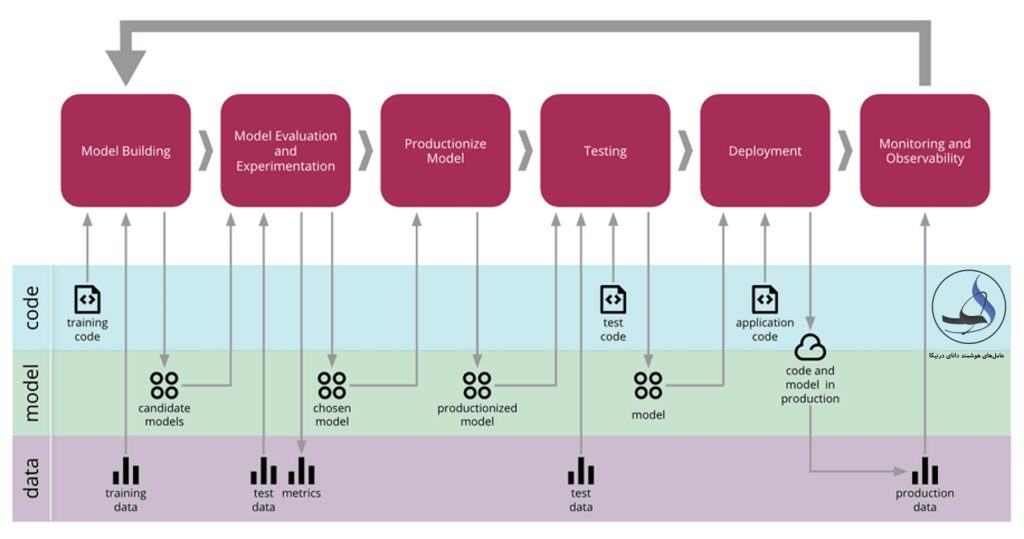
در نمودار CD4ML، به فرآیند چرخهای تولید توجه شده است که نشان میدهد اطلاعاتی که در فاز پایانی جمعآوری میشوند، بایستی به مرحله ساختمان مدل بازگردانده شوند. این مرحله به عنوان یک حلقه بسته در چرخه حیات مدل یادگیری ماشین نشان داده شده است، به این معنی که مدلها به صورت مستمر بازبینی و بهروزرسانی میشوند.
در اکثر شرکتها، ارزیابی اثرات یک مدل یادگیری ماشین از منظر تجاری و سپس تصمیمگیری درباره بهروزرسانی یا استفاده از مدل موجود، فرآیندی غیرخودکار است. اما در شرکتهای پیشرفتهتر، دادههای جمعآوری شده در مرحله نظارت به صورت خودکار وارد دادههای آموزشی جهت بهروزرسانی مدل میشوند که این کار با چالشهای جدیدی از جمله مدیریت و حفظ کیفیت دادهها همراه است.
با نگاه دقیقتر به نمودار CD4ML میتوان دریافت که دو مرحله اول نمودار به عنوان محیط تحقیقاتی و دامنه کاری دانشمندان داده است. همچنین، چهار مرحله آخر بیشتر به عنوان قلمرو مهندسی و DevOps در نظر گرفته میشود. با این حال، باید توجه داشت که این دستهبندیها ممکن است در هر شرکت با توجه به نحوه سازماندهی داخلی و نیازهای آن متفاوت باشد.
سناریوهای نظارت
همانطور که برای بسیاری از امور نرمافزاری صدق میکند، چالش اصلی در مورد قابلیت نگهداری است. استقرار و ارائه یک مدل یادگیری ماشین چالش زیادی به همراه ندارد. جایی که مسأله را پیچیده میکند، انجام این کار به صورت پی در پی، به ویژه در میان به روزرسانیهای مکرر یک مدل است. سناریوهای نظارت در حوزه مدلهای یادگیری ماشین میتوانند به شکل زیر تعریف شوند:
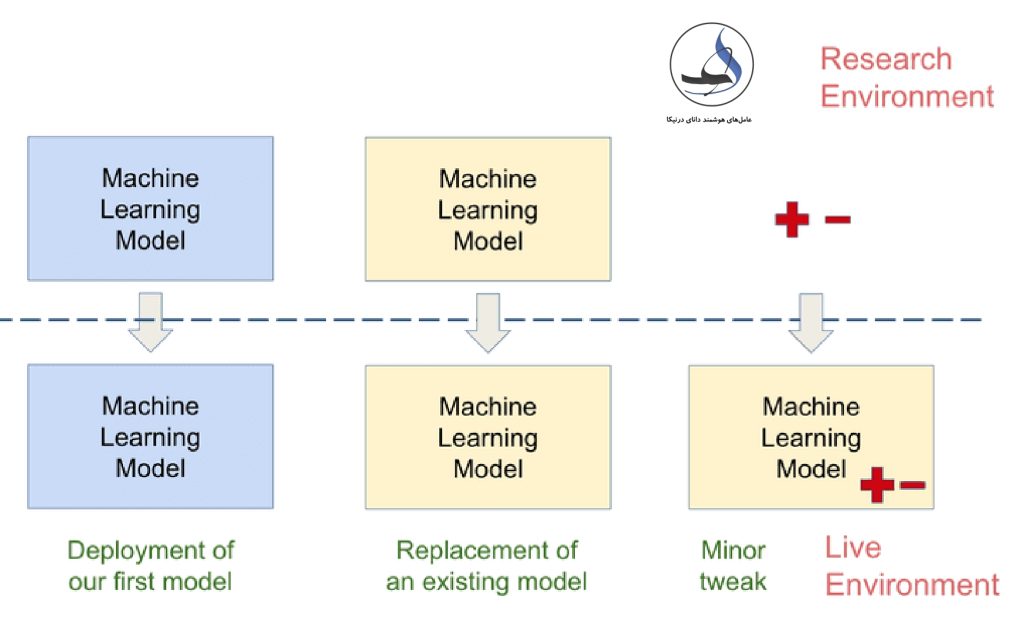
- استقرار مدل جدید: در این سناریو، مدل جدیدی که توسط تیم تحقیق و توسعه آماده شده است، مستقر میشود. این مدل جدید میتواند بهبودهایی را نسبت به مدل قبلی داشته باشد، یا با استفاده از دادههای جدید آموزش دیده باشد.
- جایگزینی کامل مدل: در این سناریو، یک مدل کاملاً متفاوت به جای مدل قبلی استقرار مییابد. این مدل جدید ممکن است از الگوریتمها و روشهای مختلفی استفاده کند و قابلیتها و عملکرد متفاوتی نسبت به مدل قبلی داشته باشد.
- بهروزرسانی مدل فعلی: در این سناریو، تغییرات کوچکی در مدل فعلی ایجاد میشود. ممکن است یک ویژگی حذف شود یا یک ویژگی جدید اضافه شود. این تغییرات میتوانند به دلیل نیاز به تطبیق با تغییرات در دادهها یا بهبود عملکرد مدل باشند.
در هر یک از سناریوهای یاد شده در بالا، نظارت بر عملکرد مدل یادگیری ماشین نقش مهمی را ایفا میکند. با استفاده از فرآیندهای نظارت، میتوان به موارد زیر اشاره کرد:
- ارزیابی عملکرد مدل: با استفاده از معیارهای ارزیابی، عملکرد مدل جدید یا بهروزرسانی شده مورد بررسی قرار میگیرد. این ارزیابی میتواند شامل دقت، صحت، بازدهی و سایر معیارهای مربوطه باشد.
- ارزیابی تأثیر تغییرات: با انجام آزمایشهای گوناگون، تأثیر تغییرات اعمال شده بر روی عملکرد و پیشبینیهای مدل مورد بررسی قرار میگیرد. این بررسی به تشخیص اینکه آیا تغییرات انجام شده، نتایج مورد انتظار را داشته است یا خیر کمک میکند.
- مقایسه مدلها: در برخی مواقع، ممکن است نیاز به مقایسه مدلهای مختلف باشد. این مقایسه میتواند بر اساس عملکرد، پیچیدگی، سرعت و سایر معیارهای مورد نیاز صورت بگیرد.
- انتخاب مدل بهتر: با توجه به نتایج نظارت و ارزیابی، مدلی که عملکرد بهتری دارد یا بهترین تطابق را با نیازهای کسب و کار ارائه میدهد، انتخاب میشود.
در کل، سناریوهای نظارت در نگهداری و بهروزرسانی مدلهای یادگیری ماشین برای اطمینان حاصل کردن از عملکرد صحیح و بهینه مدل و تطبیق آن با نیازهای تجاری استفاده میشوند.
چرا نظارت بر سیستمهای یادگیری ماشین چالشبرانگیز است؟
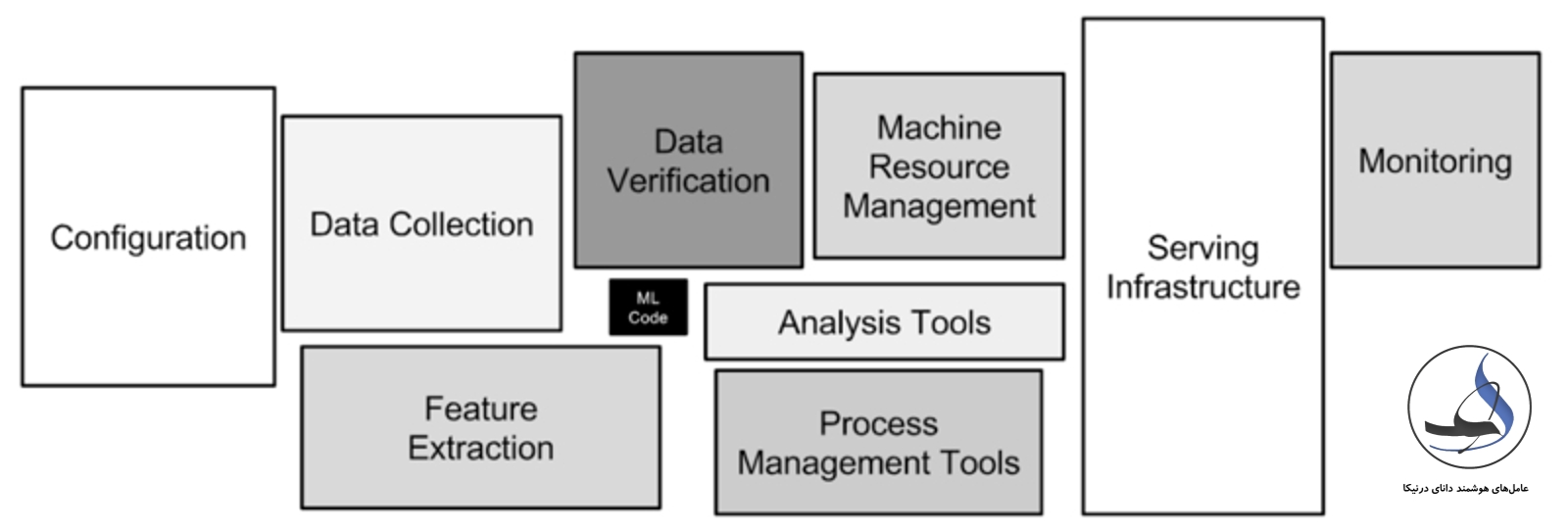
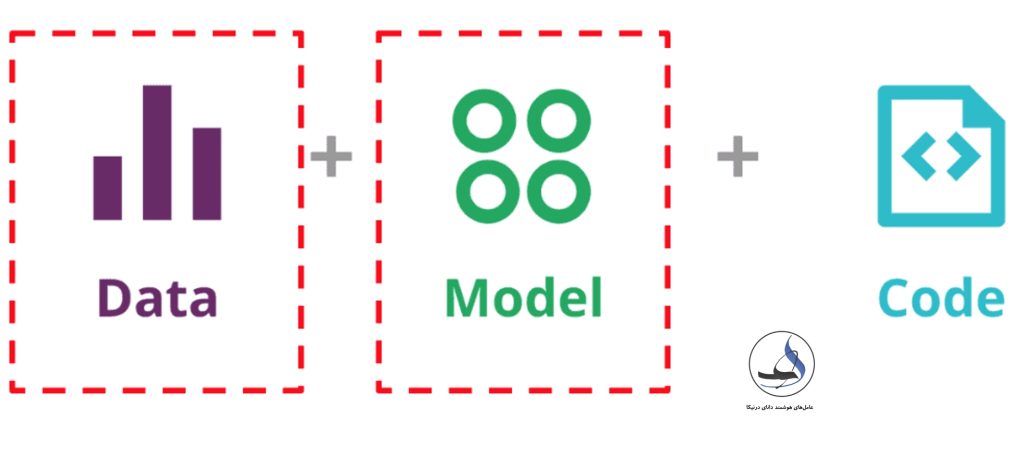
سیستمهای یادگیری ماشین، علاوه بر چالشهای معمول نرمافزارها، چالشهای خاص خود را نیز دارند. در واقع، این سیستمها بخش کوچکی از یک سیستم یادگیری ماشین را تشکیل میدهند. در حوزه سیستمهای یادگیری ماشین، پایش و نظارت بر رفتار سیستم به عنوان عنصر حیاتی و اساسی در نظر گرفته میشود. این نظارت در سه جزء اصلی بررسی میشود: کد (و پیکربندی)، مدل (با الزامات خاص سیستم یادگیری ماشین) و داده (با الزامات خاص سیستم یادگیری ماشین).
علاوه بر این، باید دو جزء دیگر را نیز در نظر بگیریم که به صورت وابستگیهای بین داده و مدل در سیستم یادگیری ماشین وجود دارند. برخلاف سیستمهای نرمافزاری سنتی که رفتار آنها تنها بر اساس قوانین مشخص شده در کد است، سیستمهای یادگیری ماشین، رفتارشان بر پایه داده هایی است که مدل با آن آموزش داده شده است. با توجه به عدم پایداری و رانش دادههای ورودی در طول زمان، بدون ردیابی و درک تغییرات در دادهها و مدل، نمیتوان به طور کامل از سیستم درکی مناسب داشت.
کد و پیکربندی به دلایل زیر پیچیدگی و حساسیت بیشتری را در یک سیستم یادگیری ماشین به همراه دارند:
- تابعیت: وقتی یک ویژگی ورودی تغییر میکند، ممکن است اهمیت، وزن یا استفاده از ویژگیهای دیگر نیز تغییر کنند. این مشکل به عنوان “تغییر هر چیزی همه چیز را تغییر میدهد” شناخته میشود. مهندسی ویژگیها در سیستم یادگیری ماشین و کد باید با دقت بسیار زیادی آزمایش شوند.
- پیکربندی: اغلب هایپرپارامترها، نسخهها و ویژگیهای مدل یادگیری ماشین در پیکربندی سیستم کنترل میشوند. کوچکترین اشتباهی در تنظیم این موارد میتواند رفتار سیستم را به شدت تغییر دهد که با تستهای نرمافزارهای سنتی قابل تشخیص نیست. این ویژگی به ویژه در سیستمهایی که مدلها به طور مداوم بهروزرسانی میشوند و به طور خودکار تغییر میکنند، بسیار مهم است.
یکی دیگر از چالشهای مدلهای یادگیری ماشین، تعداد تیمهای مختلفی است که در سیستم دخیل هستند. همکاری و هماهنگی بین اعضای تیمهای توسعه، مهندسی و عملیاتی از اهمیت بالایی برخوردار است. زیرا این تیمها باید در طول فرآیند توسعه، بهطور همزمان و هماهنگ، کارهای مختلفی از جمله آموزش مدل، بهبود کد و پیکربندی، و اعمال تغییرات در دادهها انجام دهند. همچنین، ارتباط مستمر بین این تیمها در فرآیند نظارت بر سیستم یادگیری ماشین از دیگر موارد ضروری خواهد بود.
چالش تقسیم مسئولیت در سیستمهای یادگیری ماشین
مجموعه تولید سیستمهای یادگیری ماشین شامل تیمهای زیادی است که ممکن است شامل مهندسان داده، متخصصین مدیریت حرفهای کسب و کار، تحلیلگران و اعضای دیگر در رشتههای متفاوت باشند. قبل از ادامه بحث درباره نظارت، لازم است بگوییم که این عبارت در بخشهای مختلف یک کسبوکار ممکن است مفاهیم متفاوتی را در برگیرد.
در نظر داشته باشید که وقتی از “نظارت” در میان مهندسان داده صحبت میکنیم، تمرکز برروی آزمونهای آماری ورودی و خروجی مدل یادگیری ماشین است. با این حال، در میان مهندسان و توسعه دهندگان نرمافزار، “نظارت” به معنای سلامت، تأخیر، یا میزان استفاده از حافظه است.
در فرآیند تولید سیستمهای یادگیری ماشین شما به هر دوی این دیدگاهها نیاز دارید. در حالی که در روش نرمافزاری سنتی، نظارت و قابلیت مشاهده به عهده توسعهدهنده عملیات است، در سیستم یادگیری ماشین بعید است که تیم توسعه عملیات شما تخصص لازم را برای نظارت صحیح بر مدلهای یادگیری ماشین داشته باشد (مگر اینکه دانش مهندس توسعه عملیات و دانشمند داده را در یک نفر داشته باشید، که باید او را نگه دارید و برایش افزایش حقوق بدهید). این بدان معنی است که:
- برای اینکه سیستم موثر باشد، کل تیم باید با هم بر روی نظارت کار کنند و به زبان یکدیگر صحبت کنند.
- تعریف و تمایز موضوعات مهم برای جلوگیری از ابهامها ضروری است.
با این حجم پیچیدگی، اگر فقط به نظارت مدل به صورت جداگانه بعد از استقرار فکر کنیم، عملکرد ناکارآمدی خواهیم داشت. در مرحله تولید، نظارت باید به همراه
آزمونها در سطح سیستم برنامهریزی شود.