چالشهای بسیاری در مورد پایداری و دوام مدلهای یادگیری ماشین وجود دارد. این مشکلات میتوانند به شکل مختلفی در انواع مدلهای یادگیری ماشین (Machine Learning) با شما روبرو شوند. به عنوان مثال، یک مدل با داده های کامل و به روز ممکن است به خوبی کار کند، اما با گذر زمان، ممکن است که کیفیت و دقت پیش بینی های آن کاهش یابد. همچنین، اگر داده های ورودی مدل ناقص و یا غیر قابل اعتماد باشند یا در گذر زمان تغییر کنند (رانش داده)، ممکن است که مدل نتواند به طور مطلوب عمل کند و خطاهای بیشتری تولید کند. علاوه بر این، مدلهای یادگیری ماشین معمولاً نیازمند تنظیمات و بهینه سازی هایی هستند که در برابر تغییرات طبیعی و شرایط نامطلوب مقاوم باشند.
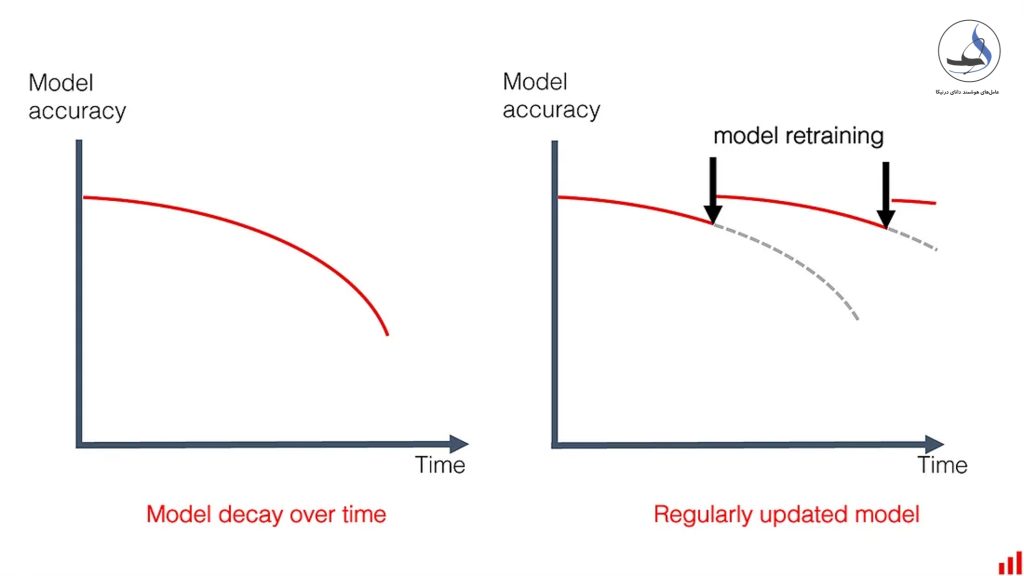
به طور کلی، برای جلوگیری از این دسته از چالشها، لازم است که داده های ورودی مدلهای یادگیری ماشین به طور دوره ای بررسی و همچنین مدل ها به شکل دوره ای بهروزرسانی شوند تا با شرایط جدید مطابقت داشته باشند و بهترین کارایی را ارائه دهند. قبل از ورود به بحث رانش دادهها، ابتدا عبارت کلیدی به کار رفته در این متن را به منظور درک بهتر اطلاعات و برقراری ارتباط با این مقاله توضیح میدهیم.
کاهش کیفیت مدل یادگیری ماشین (model decay)
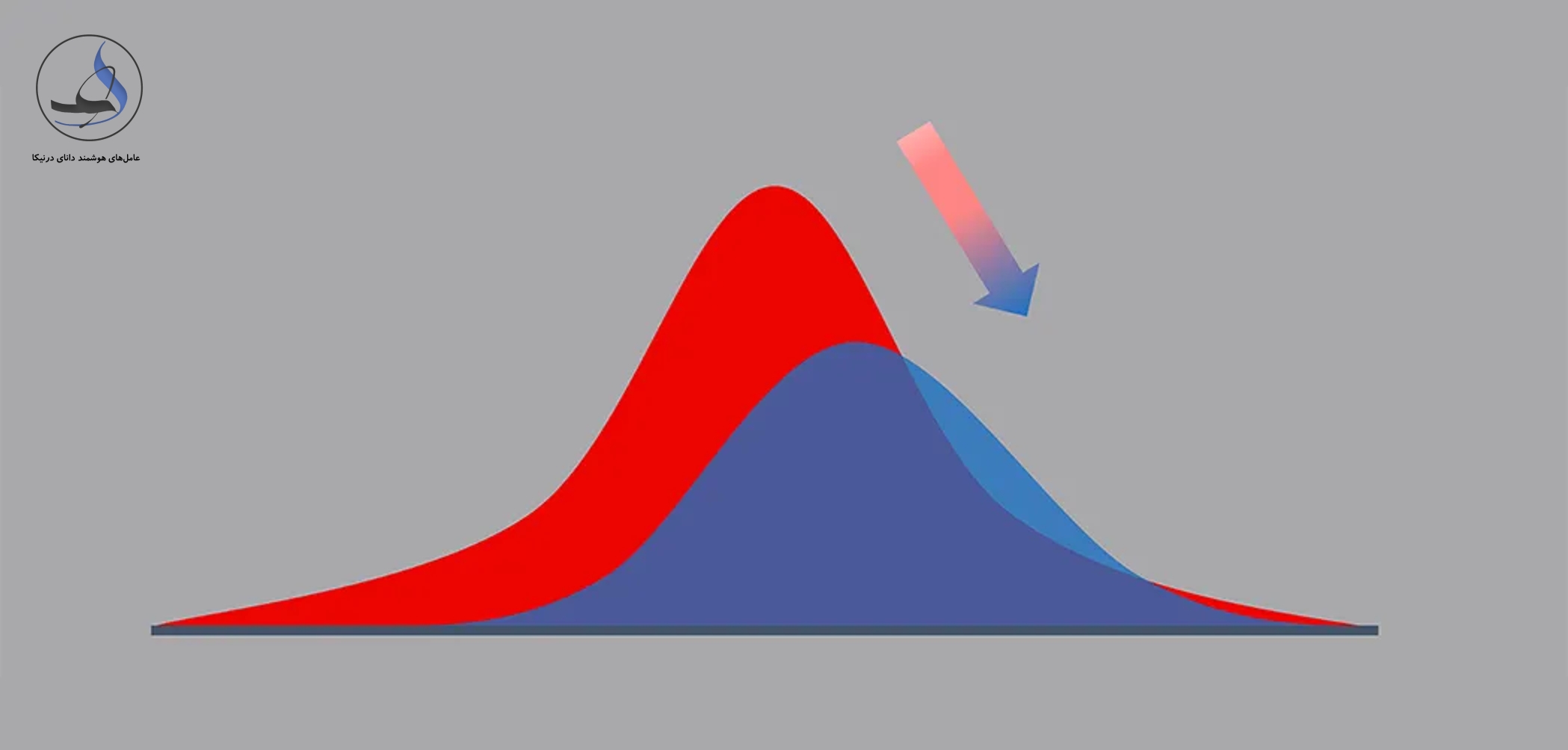
مدلهای یادگیری ماشین، روشهای مبتنی بر هوش مصنوعی هستند که برای پیشبینی و تحلیل داده ها استفاده میشوند. با این حال، این مدلهای یادگیری همواره کیفیت بالایی نخواهند داشت و ممکن است که با گذر زمان، دچار کاهش دقت شوند. این پدیده به نام کاهش کیفیت مدل، راندگی مدل یا کدگذاری بیش از حد شناخته میشود.
دو دلیل اصلی برای کاهش کیفیت مدل وجود دارند. اول، کدگذاری بیش از حد که منجر به از دست رفتن اطلاعات مهم در داده ها و ایجاد اطلاعات اضافی غیرضروری میشود. دوم، رانش مفهوم که به معنای ناپدید شدن ارتباطات یا تغییر در رویه های داده ها است.
به همین منظور لازم است تا با پایش معیار کیفیت مدل مانند دقت، نرخ خطای متوسط یا برخی شاخص های کسب و کار پایین دستی مانند نرخ کلیک، کیفیت مدل یادگیری ماشین را به طور پیوسته مورد تحلیل قرار دهیم. کیفیت برخی از مدلها در طول زمان میتواند بدون بهروزرسانی تا سالها باقی بماند، مانند برخی از مدل های بینایی کامپیوتری و زبانی و یا هر سیستم تصمیمگیری که در محیطی پایدار و مستقل آموزش داده شده باشد. از طرف دیگر، برخی از مدل ها ممکن است نیاز به بازآموزی روزانه با داده های جدید داشته باشند.
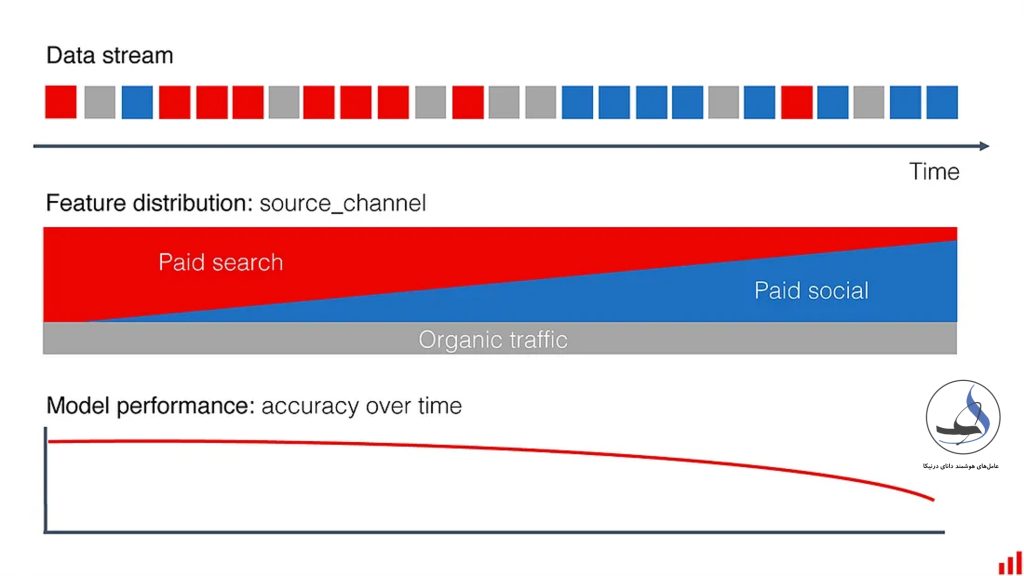
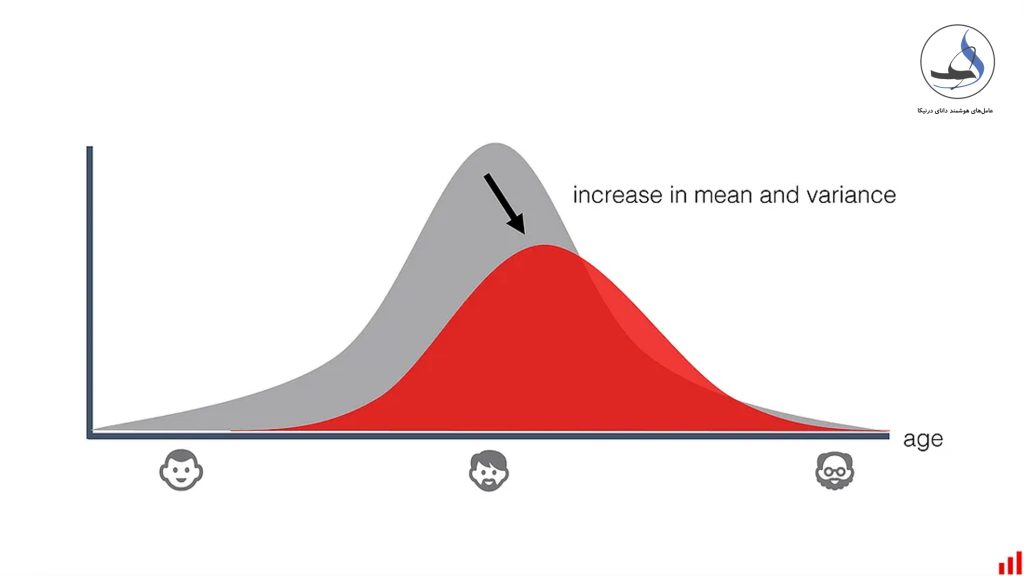
رانش داده (Data Drift)
در واقع، رانش داده یا data drift یک پدیده طبیعی است که بیانگر تغییراتی است که در دادههای ورودی در طول زمان رخ میدهد. به عنوان مثال، در صورتی که شما یک مدل یادگیری ماشین برای پیشبینی بازار سهام با استفاده از داده های سال ۲۰۲۰ آموزش داده باشید، اگر داده های بازار در سال ۲۰۲۳ تغییر کنند، مدل شما برای پیشبینی بازار در سال ۲۰۳۰ قابل استفاده نیست.
مدل سازی تمایل (propensity modeling)
مدل سازی تمایل یکی از روشهایی است که به کار میرود تا احتمال خرید کاربران جدید و قدیمی را پیشبینی کند و پیشنهادهایی برای آنها ارائه دهد. در این روش، از الگوریتمهای یادگیری ماشین و شبکههای عصبی برای آموزش مدل استفاده میشود. برای ساخت یک مدل تمایل، ابتدا دادههایی را جمع آوری میکنیم که شامل اطلاعاتی مانند سن، جنسیت، محل سکونت، نوع مرورگر و … باشد. سپس این دادهها را به کمک الگوریتمهای یادگیری ماشینی به یک مدل آموزش میدهیم و احتمال خرید را برای هر کاربر پیشبینی میکنیم. با استفاده از این اطلاعات، میتوانیم به هر کاربر پیشنهادهایی را بدهیم که مطابق با علایق و نیازهای او باشد و باعث افزایش فروش شود.
اما مانند هر مدل دادهکاوی دیگر، مدل سازی تمایل نیز ممکن است با مشکل رانش مواجه شود. به این معنی که با تغییر در دادهها (رانش داده) یا رفتار کاربران، دقت و عملکرد مدل کاهش پیدا کند. در چنین شرایطی، برای حل این مشکل باید مدل یادگیری ماشین را با دادههای جدید آموزش داد یا آن را برای بخش جدید بازسازی کرد. همچنین، بررسی و اصلاح دادههای ورودی و انتخاب بهترین ویژگیها میتواند به دقت و عملکرد بهتر مدل یادگیری ماشین کمک کند.
انحراف آموزش-خدمات (Training-serving skew)
یکی دیگر از عبارات کلیدی در مبحث کیفیت مدلهای یادگیری ماشین، انحراف آموزش-خدمات است که اغلب مواقع با مفهوم رانش داده اشتباه گرفته می شود و به جای آن استفاده می شود. تفاوت اصلی انحراف آموزش-خدمت با رانش داده در علت بروز انحراف در دادگان ورودی است که به موجب آن کیفیت مدل کاهش یافته است. این مشکل اغلب زمانی پیش می آید که مدل بر روی داده های ساختگی و یا دادههای تمیز آموزش داده شده است که نماینده دنیای واقعی نیستند یا نمایش آن ها از دنیای واقعی ناقص است. به عنوان مثال، فرض کنید که یک مدل دسته بندی صورتحساب با استفاده از یک مجموعه محدود تصاویر آموزش دیده شده است. با اینکه در مرحله آزمایش، این مدل عملکرد خوبی از خود نشان داده است اما در محیط های تولید، تنوع در پر کردن صورتحساب ها توسط مردم و یا کیفیت پایین عکس های اسکن شده باعث کاهش کیفیت عملکرد می شود. برای رفع این مشکل، مجموعه داده باید به گونه ای آماده شود که نماینده دنیای واقعی باشد و تفاوت های محتمل بین داده های ساختگی و واقعی را در نظر بگیرد.
به طور مثال، تیم سلامت گوگل به تازگی با یک چالش مشابه روبرو شد. آنها یک مدل بینایی ماشین را برای تشخیص علائم رتینوپاتی از تصاویر اسکن چشم طراحی کردند. از آنجا که هنگام بهره برداری در دنیای واقعی، این تصاویر غالباً در شرایط نوری ضعیف گرفته میشدند، عملکرد مدل در مقایسه با شرایط آزمایشگاهی (که تصاویر ورودی از نور بالایی برخوردار بودند) کاهش چشمگیری داشت.
در بیشتر مواقع انحراف آموزش-خدمت به این معنی است که توسعه مدل باید ادامه یابد. در صورتیکه مجموعه دادگان آموزشی شما غنی باشد تنها کافی است که با انجام یک سری از پیشپردازش ها، داده ها را به شکل داده های دنیای واقعی نزدیک کنید و مدل خود را با این داده های جدید سازگار نمایید. در غیر این صورت، باید ابتدا مجموعه داده جدید را جمع آوری و برچسبگذاری کرده و سپس با آموزش مدل جدید و یا سازگارسازی آن، به رفع این مشکل بپردازید.